Augento AI
Welcome to Augento!
Augento is a platform for continuous finetuning of open-source language models by reinforcement learning.
Why Augento?
We all know it, agents fail. Most of the time because of trivial mistakes and formatting issues. Teaching your model to avoid these errors is hard. Yelling at the model in the system prompt works for a few edge cases but ultimately does not scale. Classical post-training methods, like supervised fine tuning, are in theory the right thing to do, but require large amounts of explicit post training data, which nobody wants to generate or collect.
Therefore we built a platform to solve that. With Reinforcement Learning.
Unlike query optimization, we actually produce a different model optimized on your tasks.
Unlike supervised finetuning, you don’t have to collect and provide an explicit dataset of training samples.
We are non-invasive in your existing agent setup and seamlessly work with all agent framework and are completely independent of auxiliary optimizations, like RAG pipelines, etc.
How it works
Currently, the Augento Platform can produce
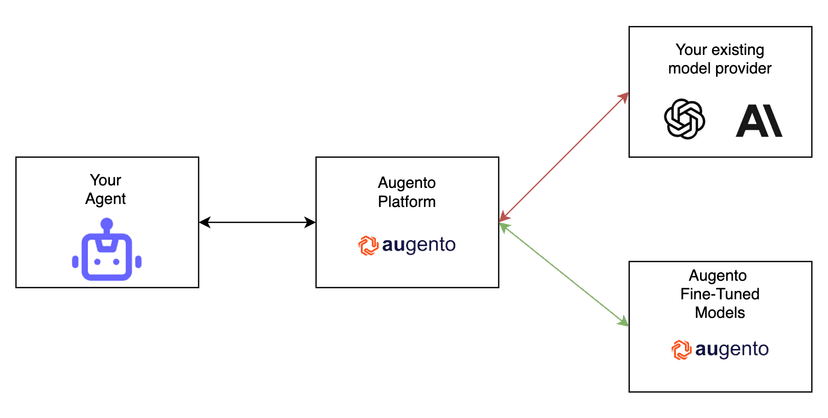
Hooking into your running system
Augento will hook into your running production system and displays you all runs your agent took. This is done in a minimal invasive way, you provide your OpenAI API key, we give you another API key + URL, which you put into you OpenAI constructor call
Monitor Your Agent And Select Problematic Queries
In the Augento Platform, you monitor the runs your agent took and select a subset of the queries as training queries. This will be the queries, your agent will be trained on during RL training.
Provide A High Level Reward Function
You provide a reward function which will grade how good the output of the models is during training.
Train A Finetuned Model
You trigger a RL training job on the Platform. This will train an open-source reasoning model on the training queries and reward function you provided.
Switch To The Model In One Click
We will train and host the finetuned model for you. You can switch to your finetuned model (instead of OpenAI) in one click in your model view.
Common Use Cases
In the current iteration, the Augento Platform offers Reinforcement Learning for Verifiable Domains, like teaching agents how to code, reason, play chess and generally produce correct structured output.
In the near future, we will also support an alignment mode, where you can teach your agent behaviours by talking to them in natural language. Stay tuned!